Redes para classificação de imagens e reconhecimento de objetos em cenas

Contents
- 1 Assuntos Gerais & Explanações
- 2 Modelos Tradicionais de Classificação de Imagens
- 3 Tutoriais
Assuntos Gerais & Explanações
Dê uma olhada nesta aula de Stanford para se inspirar antes de ler o material abaixo:
Tutoriais Gerais
- Medium: Jonathan Hui – Object Detection Series
- Aprendizagem de Máquina é Divertido! Parte 3 – Deep Learning e Redes Neuronais Convolutivas – Um raríssimo texto em Português do Prof. Josenildo Costa da Silva do IFMA
- Aprendizagem de Máquina é Divertido! Parte 4 – Reconhecimento Facial Moderno com Deep Learning – Outro raríssimo texto em Português, também do Prof. Josenildo Costa da Silva do IFMA
ImageAI
Esta API é uma abstração de TensorFlow com Keras. Funciona basicamente como a FastAI library por cima do pytorch.
Discussão dos Modelos
- Medium: Design choices, lessons learned and trends for object detections?
- Medium: What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
- Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
Modelos Tradicionais de Classificação de Imagens
A detecção de objetos costuma ser modelada como um problema de classificação: você toma janelas de tamanhos fixos a desliza essas janelas por sobre a imagem, alimentando um classificador de imagens com os retalhos que a janela extrai da imagem.

Aqui abordamos alguns modelos famosos de Redes Neurais Convolucionais para processamento de imagens.
AlexNet
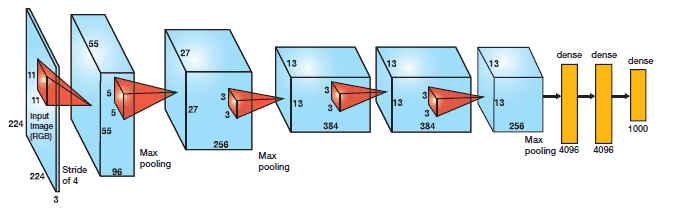
Em 2012, AlexNet ultrapassou de forma significativa todos os outros competidores e venceu a competição Large Scale Visual Recognition Challenge (ILSVRC) de 2012 reduzindo o top-5 error de 26% para 15.3%. O top-5 error do segundo colocado, que não foi uma variação de CNN, foi de 26.2%.
A rede possui uma arquitetura muito similar à LeNet desenvolvida por Yann LeCun mas é muito mais profunda, com mais filtros por camada e com camadas convolucionais sobrepostas. Ela consistiu de convoluções 11×11, 5×5,3×3, max pooling, dropout, data augmentation, ReLU activations e SGD com momento. Utilizou ReLU activations depois de cada camada convolucional e também depois de cada camada completamente conectada (backpropagation tradicional).
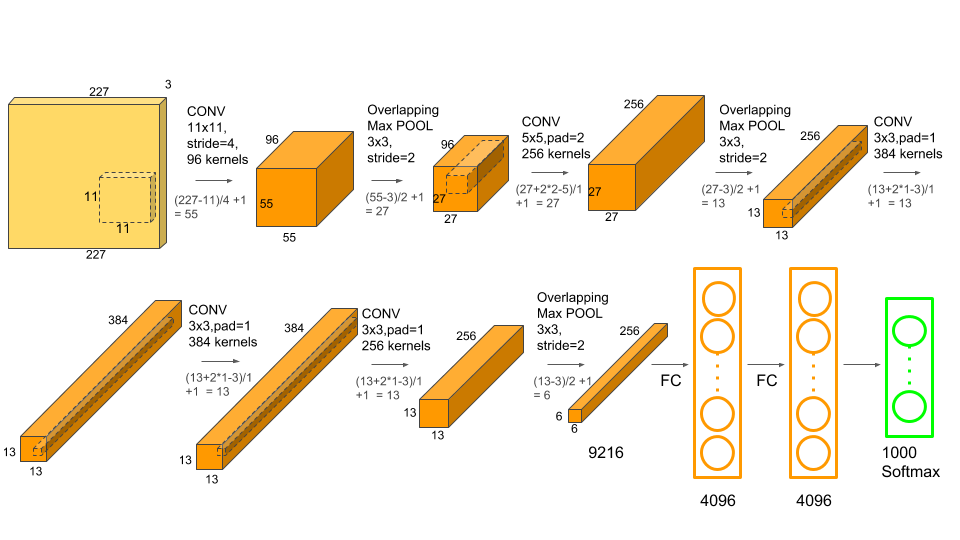
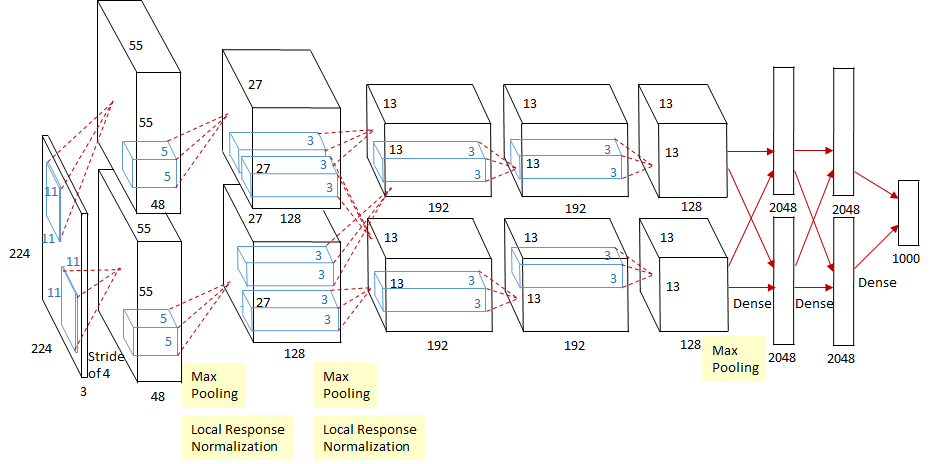
AlexNet foi treinada por 6 dias consecutivos em um par de Nvidia Geforce GTX 580 GPUs, razão pela qual e arquitetura de rede original é dividida em duas pipelines separadas, como mostra a figura abaixo. AlexNet foi projetada pelo SuperVision Group, composto por Alex Krizhevsky, Geoffrey Hinton e Ilya Sutskever:
Implementações e Links sobre AlexNet
- AlexNet é parte integrante do pacote Torchvision.Models de Pytorch (https://pytorch.org/docs/stable/torchvision/models.html) e, com isto, possui uma implementação de excelente qualidade como parte deste framework de CNNs em Python.
- O pacote Keras.Applications não possui uma implementação de AlexNet.
- Git oficial de TensorFlow contendo AlexNet
- engMRK::AlexNet Implementation Using Keras
VGG
A competição Large Scale Visual Recognition Challenge (ILSVRC) de 2014 observou o aparecimento de duas novas propostas de CNNs. GoogLeNet e VGGNet.
VGGNet foi desenvolvida por Simonyan and Zisserman e o seu modelo pmais conhecido é composto por 16 camadas convolucionais. É um modelo muito elegante por sua uniformidade de arquitetura. Possui similaridades a AlexNet, mas utiliza apenas convoluções 3×3 e as compensa com muitos filtros. A rede foi treinada em 4 GPUs por 2 a 3 semanas.
VGGNet é considerada a rede preferida pela comunidade para aprendizado pro transferência pois sua arquitetura uniforme é boa para extrais características de imagens. Assim, VGG tem sido utilizada como extrator de características-base para muitas outras coisas, como Unet, TernausNet e várias outras redes.
VGG16 no entanto, possui 138 milhões de parâmetros, o que a torna uma rede ruim para treinar a partir do zero.

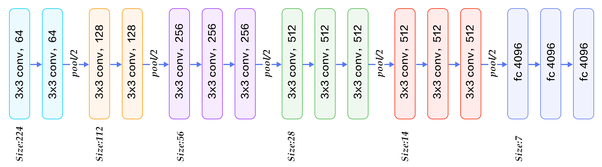
Arquitetura de VGG16
Modelos de VGG:
- VGG11
- VGG13
- VGG16
- VGG19
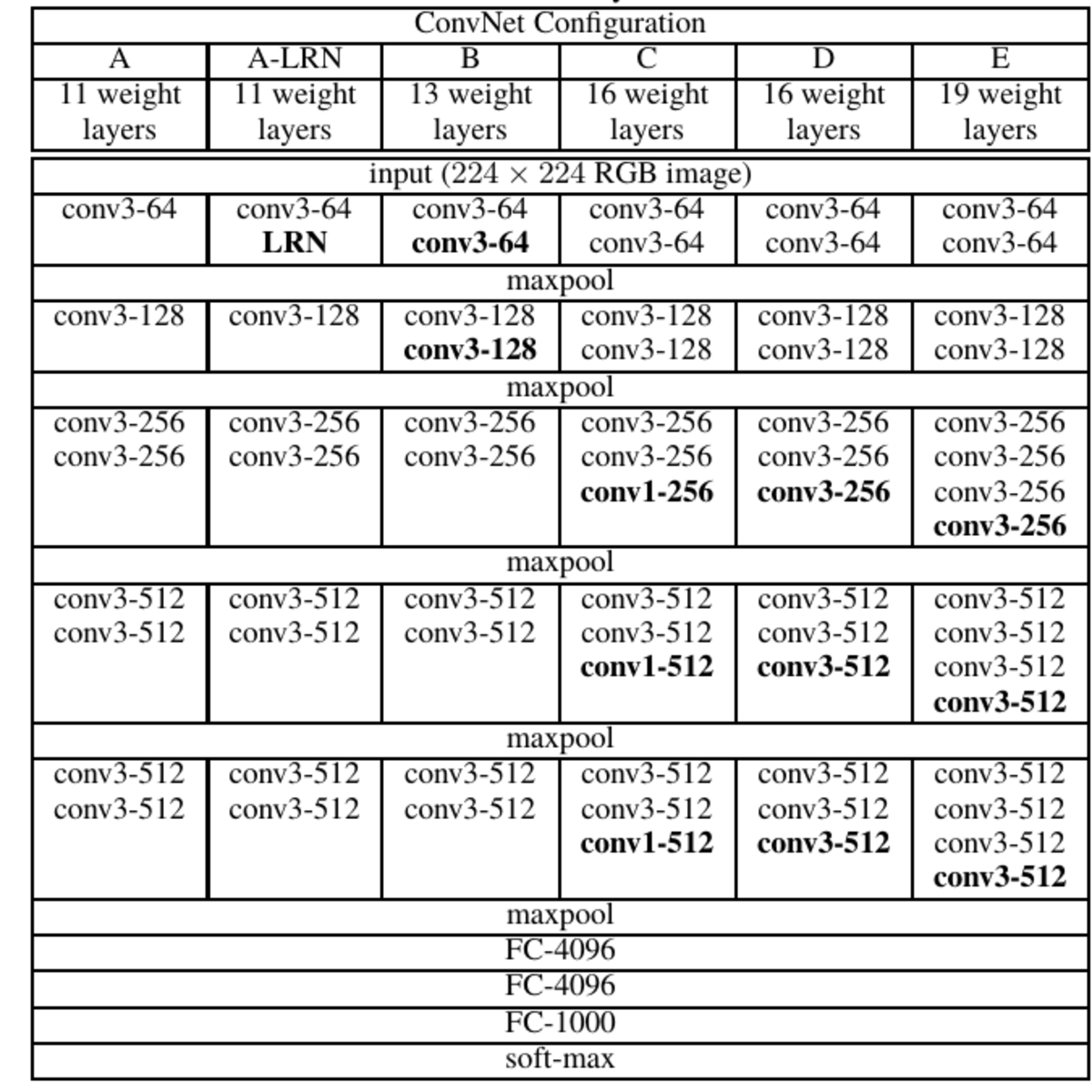
Configurações de VGG em Torchvision
Implementações e Material sobre VGG
- VGG16 é parte integrante do pacote Keras.Applications e, com isto, possui uma implementaçõe de excelente qualidade como parte deste framework de CNNs em Python. Veja o tutorial Satya Mallick: Keras Tutorial : Transfer Learning using pre-trained models em nossa página de Aprendizado por Transferência e Ajuste Fino para aprender a usar Keras.Applications.
- VGG11, 13, 16, e 19 são também parte integrante do pacote Torchvision.Models de Pytorch (https://pytorch.org/docs/stable/torchvision/models.html) e, com isto, possuem uma implementaçõe de excelente qualidade como parte deste outro framework de CNNs em Python. Um bom exemplo de como usar está aqui: freeCodeCamp::Keras vs PyTorch: how to distinguish Aliens vs Predators with transfer learning.
- engMRK::VGG16 – Implementation Using Keras
GoogLeNet/Inception (ou Inception V1)
O vencedor da competição Large Scale Visual Recognition Challenge (ILSVRC) de 2014 foi GoogleNet(a.k.a. Inception V1) da Google, obtendo um top-5 error de apenas 6.67%!
Isto estava muito próximo da performance humana, a qual so organizadores da competição passaram a ter de avaliar. Essa avaliação é difícil de executar e experimentos demonstraram que, para bater a acurácia de GooGleNet, treino dos participantes era necessário. Após alguns dias de treino, um especialista humano (Andrej Karpathy – Tesla Automóveis) foi capaz de atingir um top-5 error de 5.1%(simples) e 3.6%(ensemble).
GooGleNet usa um modelo de CNN inspirado por LeNet, mas que implementou um novo conceito: o módulo de incepção. Ela usou batch normalization, distortions das imagens e RMSprop. O módulo de incepção é baseado em várias convoluções pequenas com o objetivo de drasticamente reduzir o número de parâmetros e facilitar o treinamento . GooGleNet possui uma arquitetura de 22 camadas, mas reduziu o número de parâmetros de 60 milhões (AlexNet) para 4 milhões.
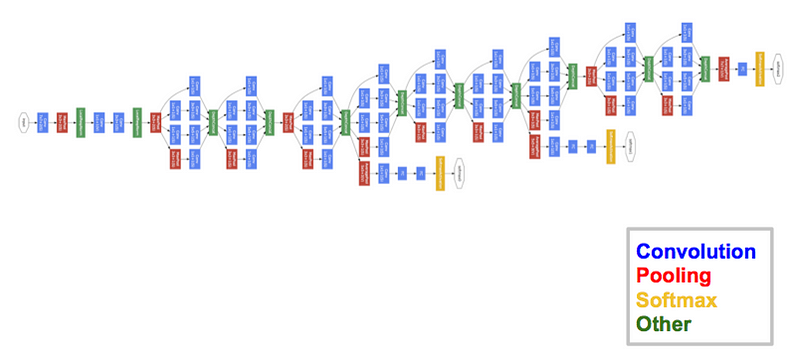
Arquitetura de GooGleNet (Inception V1)
Nomenclatura
A palavra inception não existe na Língua Inglesa. O nome Inception vem do filme de ficção científica homônimo (https://www.imdb.com/title/tt1375666/ – “A Origem” em Português) produzido no Reino Unido em 2010. No enredo do filme é desenvolvido um mecanismo que permite “injetar” (incept) ideias e memórias em outras pessoas criando, assim, uma forma muito mais poderosa do que qualquer propaganda subliminar para controlar o pensamento das pessoas.
Como nesse modelo de rede o termo Inception acaba sendo utilizado para designar uma ação de aprendizado interno de representação bem definido, vamos, nesta disciplina, criar o neologismo Português incepção.
Arquitetura
A rede de incepção usa, além de vários componentes hgetrogêneos, uma séria módulos bastante homogêneos entre si e com uma estrutura pré-definida, chamados módulos de incepção. Esses módulos são utilizados de forma repetida na rede Inception e em suas sucessoras.
A visão de alto nível (ingênua) da primeira versão desses módulos de incepção é dada pela figura abaixo:
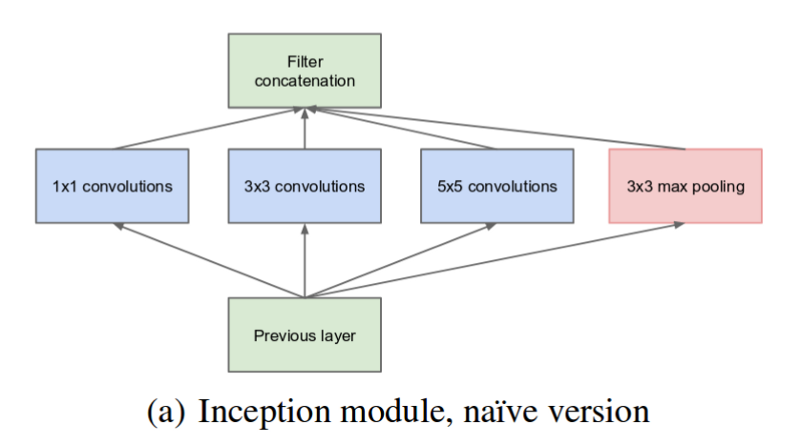
A ideia básica é tornar a rede “mais larga” para que ela possa melhor trabalhar com kernels adaptados às variações impostas por objetos de interesse de uma mesma classe mas com tamanhos aparentes muito diferentes em imagens. Tornando a rede mais larga e menos profunda e, por conseguinte, menos dada a superespecialização (overfitting), esperava-se poder treinar maiores variações nos objetos nas iamgens sem sobretreinar a rede, mantendo generalidade.
Para isso um módulo de incepção realiza convoluções com três tamanhos diferentes de kernel em paralelo a cada nível, como está mostrado na imagem acima. Um canal direto e que realiza apenas max pooling também é provido. Assim o sinal possui 4 caminhos diferentes de propagação do sinal: três extrações de caracterísitcas e uma seleção direta de sinais fortes.
Com o objetivo de reduzir a complexidade computacional gerada pela imensidão de parâmetros de um módulo de incepção, foram introduzidas convoluções 1×1 para preprocessar o sinal de entrada das camadas convolucionais 3×3 e 5×5. O mesmo foi realizado após a camada mas pooling. A versão “realista” do módulo de incepção fica então como na figura abaixo:
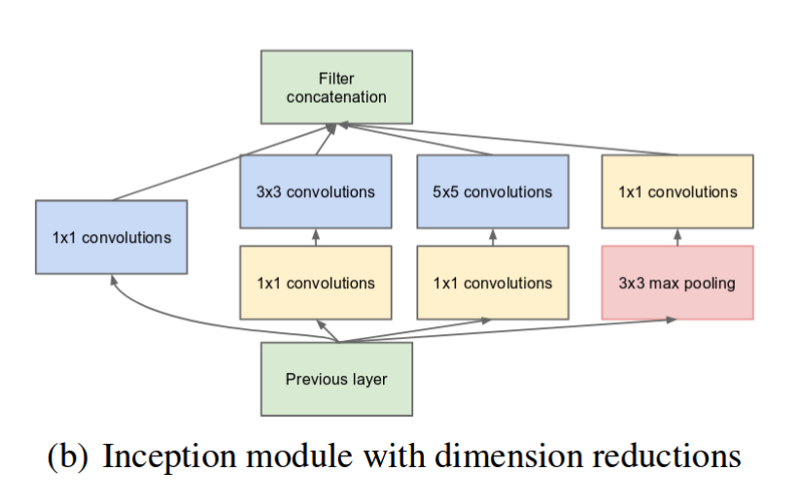
Inception V1/GooGleNet possui 9 módulos de incepção empilhados uns sobre os outros. A figura abaixo repete a arquitetura do início desta seção, com as seguintes marcações:
- Retângulo laranja: o “caule” da rede e que realiza convoluções de inicialização;
- Os ramos marcados em roxo são classificadores auxiliares;
- Os 9 blocos em seqüência, homogêneos, de camadas são os módulos de incepção;
- A saída do último módulo de incepção emprega average pooling.
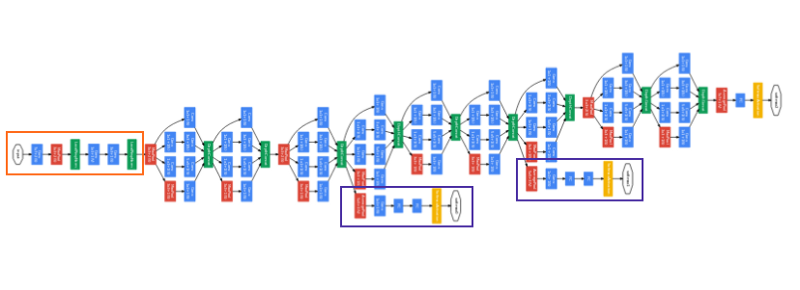
É uma rede muito profunda, com 22 camadas (27 se você contar as camadas de pooling entre módulos) e, nesta arquitetura, é uma rede sujeita ao problema de gradientes evanescentes. Em 2014 esse problema não estava tão estudado ainda e nesta rede, para evitar que o meio da rede “morresse”, foram criadas duas saídas classificadoras auxiliares (marcadas em roxo no desenho acima) conectadas a dois módulos de incepção e que aplicam softmax à sapida desses módulos. Com elas a função de perda é calculada como uma soma ponderada de perdas da rede em três pontos diferentes da rede: peso 0,3 para cada uma das saídas auxiliares e 0,4 para a saída real.
Links:
Inception V2 & V3
Inception V2 e V3 foram propostas no mesmo artigo. Várias melhorias foram apresentadas e, na prática, hoje utiliza-se Inception V3.
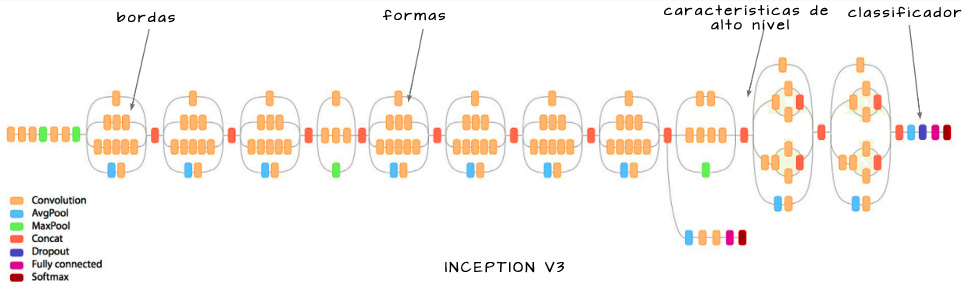
Todas as melhorias apresentadas são refinamentos a nível de detalhe: conceitualmente não há grande diferença entre Inception V1, V2 e V3. Chama a atenção
- introdução dos módulos de incepção heterogêneos (desenvolvidos mais em Inception V4);
- redução das saídas auxiliares a apenas uma (descobriu-se que só possuem influência significativa próximo do final do treinamento).
Para uma discussão em detalhe das melhorias introduzidas, veja Towards Data Science::A Simple Guide to the Versions of the Inception Network.
Implementações:
- Inception V3 é parte integrante do pacote Keras.Applications e, com isto, possui uma implementaçõe de excelente qualidade como parte deste framework de CNNs em Python. Veja o tutorial Satya Mallick: Keras Tutorial : Transfer Learning using pre-trained models em nossa página de Aprendizado por Transferência e Ajuste Fino para aprender a usar Keras.Applications.
- Inception V3 também parte integrante do pacote Torchvision.Models de Pytorch (https://pytorch.org/docs/stable/torchvision/models.html) e, com isto, possui uma implementaçõe de excelente qualidade como parte deste outro framework de CNNs em Python. Um bom exemplo de como usar está aqui: freeCodeCamp::Keras vs PyTorch: how to distinguish Aliens vs Predators with transfer learning.
- Git oficial: Inception in TensorFlow com instruções detalhadas de como usar, treinar do zero e retreinar/fazer ajuset fino.
ResNet
ResNet foi apresentada na ILSVRC 2015, a qual ela venceu com uma performance no top-5 error rate de 3,57%. A Rede Neural Residual (ResNet) apresentada por Kaiming He et al introduziram uma nova arquitetura com duas características principas:
- “identity shortcut connections”: uma estratégia de “atalhos” ou “conexões de salto” que pulam pares de grupos de camadas convolucionais. São também chamadas gated units ou gated recurrent units, apesar de não apresentarem uma recorrência no sentido tradicional dos modelos de redes neurais recorrentes;
- foco pesado em normalização de lotes (batch normalization).
Graças a este enfoque eles foram capazes de treinar uma rede com até 152 camada, mas que possuía uma complexidade final menor do que VGG.
Identity shortcut connections
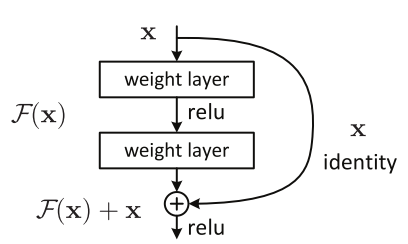
De forma simplificada, a ideia dos atalhos em ResNet é evitar que a rede, muito profunda, morra por evanescimento de gradientes através do empilhamento de mapeamentos de identidades que, do ponto de vista matemático, segundo os autores, estão simplesmente empilhando camadas que nao fazem nada. Como isso, como mostra a figura acima, ResNet utiliza, num determinado ponto, um sinal que é a soma do sinal produzido pelas duas camadas convolucionais anteriores somado ao sinal transmitido diretamente do ponto anterior a estas camadas, juntando um sinal processsado com um sinal de uma etapa anterior no processamento. O artigo Towards Data Science: An Overview of ResNet and its Variants entra em detalhes sobre esta arquitetura e suas conseqüências para modelos similares, listando redes similares como Highway Networks, DenseNet, ResNeXt e as Deep Networks with Stochastic Depth, que abandonam camadas inúteis durante o treinamento e podem iniciar um treinamento como redes de até 1200 camadas….
- Leia mais sobre os blocos residuais aqui: Towards Data Science::Residual blocks — Building blocks of ResNet
Modelos de ResNet
A figura abaixo mostra uma comparação entre:
- ResNet de 34 camadas,
- uma rede de 34 camadas usando uma mistura de um arquitetura VGG-like e características de preprocessamento de ResNet;
- VGG19, destacando os blocos de camadas com funcinalidade similar às regiões de camadas de ResNet.
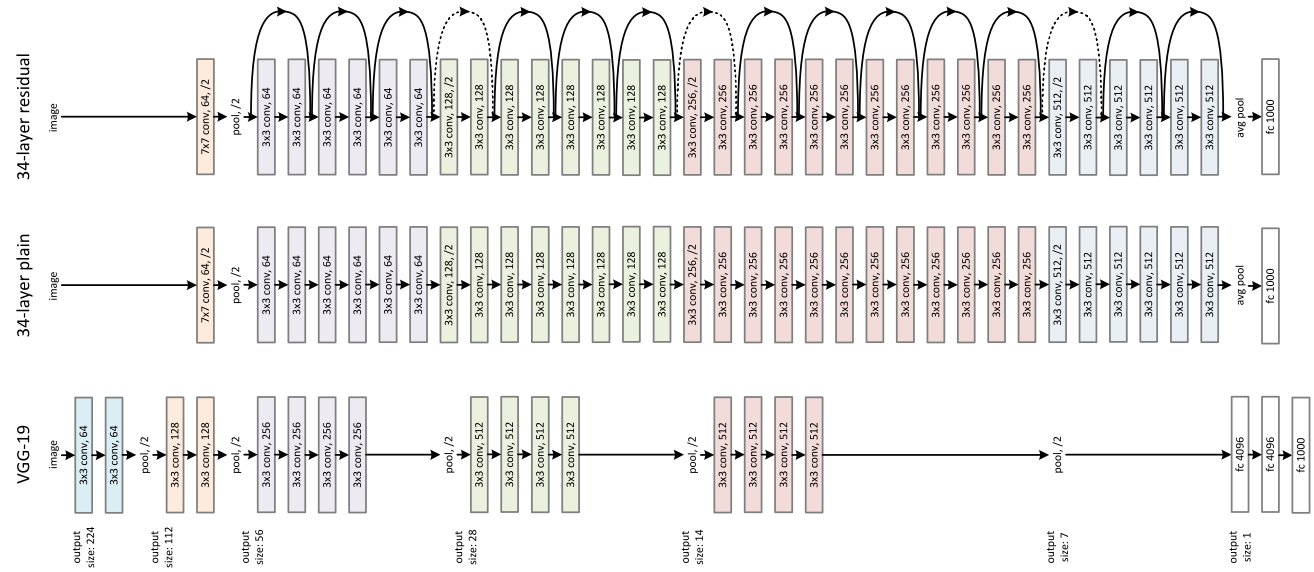
A ideia geral da arquitetura de ResNet é uma estrutura de quatro tipos de blocos de camadas, enumerados de 0 a 3, que podem ser usados para construir redes de diferentes profundidades. ResNet50, por exemplo, usa uma configuração (3, 4, 6, 3). A figura abaixo mostra uma visão abstrata com uma configuração (3, 3, 3, 3):
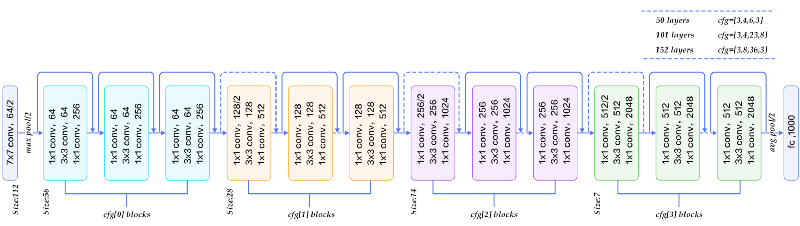
A figura abaixo compara os diferentes modelos específicos de ResNet descritos na literatura, observe que ResNet 18 e 34 usam arquiteturas mais simples para os blocos de tipos 2 e 3 (conv4_x e conv_5x):

Links para Material sobre ResNet
- Artigo original: K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
- Towards Data Science: An Overview of ResNet and its Variants
- Medium::Residual Networks (ResNets)
Implementações:
- ResNet50 é parte integrante do pacote Keras.Applications e, com isto, possui uma implementaçõe de excelente qualidade como parte deste framework de CNNs em Python. Veja o tutorial Satya Mallick: Keras Tutorial : Transfer Learning using pre-trained models em nossa página de Aprendizado por Transferência e Ajuste Fino para aprender a usar Keras.Applications.
- ResNet é também parte integrante do pacote Torchvision.Models de Pytorch (https://pytorch.org/docs/stable/torchvision/models.html) e, com isto, possui uma implementaçõe de excelente qualidade como parte deste outro framework de CNNs em Python. Diferentemente de Keras, Pytorch possui todas as implementações-referência de ResNet:
- ResNet-18
- ResNet-34
- ResNet-50
- ResNet-101
- ResNet-152
- Um bom exemplo de como usar está aqui: freeCodeCamp::Keras vs PyTorch: how to distinguish Aliens vs Predators with transfer learning.
- Git oficial de TensorFlow: ResNet in TensorFlow
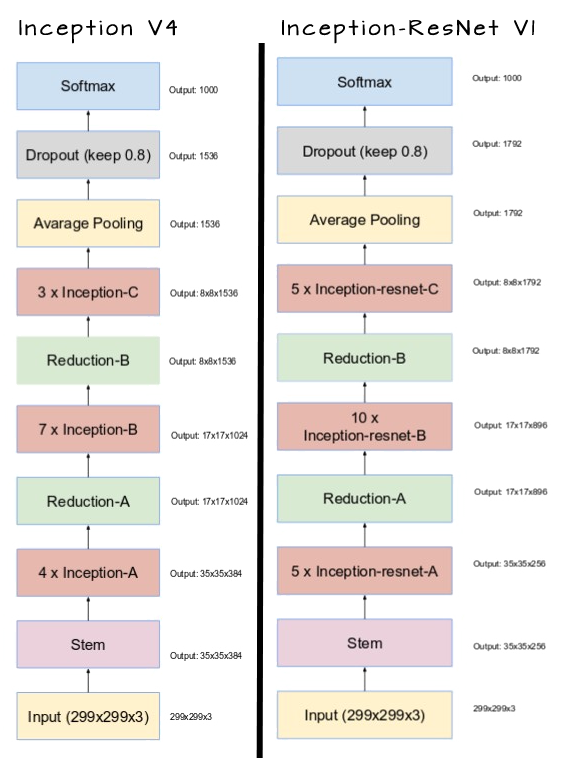
Inception V4
Inception V4 e Inception-ResNet foram apresentadas no mesmo artigo. É interessante, porém, discutí-las em separado. A arquitetura de alto nível de Inception V4 é mostrada ao lado: os módulos de incepção tipos A, B e C são explicados abaixo.

O “caule” da rede foi modificado como mostra a figura abaixo:
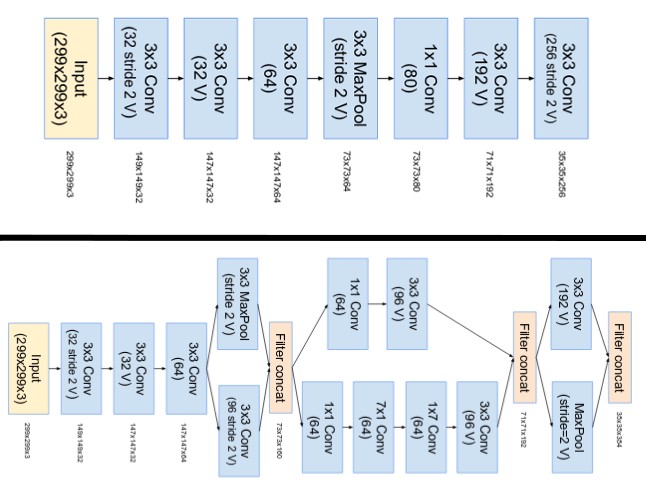
Principal modificação de Inception V4 foi a uniformização dos módulos de incepção com o objetivo de melhorar a performance. Foram criados 3 módulos padronizados, chamados de modulos de incepção A, B e C:
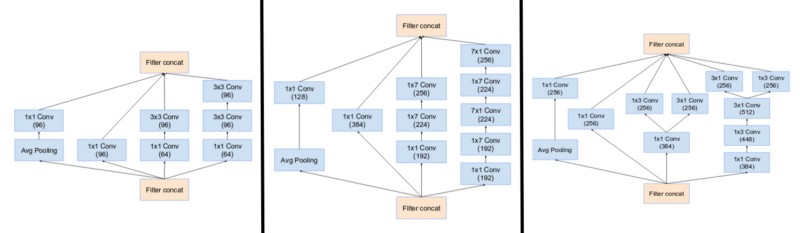
Inception V4 introduziu também blocos de redução especializados e que são utilizados para modificar a largura e altura do grid.

Links:
Implementações:
- Uma implementação de Inception V4 em Keras com pesos para TensorFlow e para Theano: https://github.com/titu1994/Inception-v4
- Outra implementação de Inception V4 (Kent Sommer) em Keras: https://github.com/kentsommer/keras-inceptionV4 (Obs.: Esta implementação produziu erros menores do que os do artigo original. Aqui: Top5 = 4,88% e Top1 = 19,54%)
- Git oficial de TensorFlow contendo Inception V4
Inception-ResNet
A evolução de Inception V3 e V4 foi a de utilizar uma arquitetura capaz de utilizar conecções residuais, da mesam forma de ResNet. Foram criadas Inception-ResNet v1 e v2, sendo a primeira uma evolução de Inception V3 e a segunda de V4.
Links:
Implementações:
- Inception-ResNet V2 é parte integrante do pacote Keras.Applications e, com isto, possui uma implementaçõe de excelente qualidade como parte deste framework de CNNs em Python. Veja o tutorial Satya Mallick: Keras Tutorial : Transfer Learning using pre-trained models em nossa página de Aprendizado por Transferência e Ajuste Fino para aprender a usar Keras.Applications.
Comparando Inception V4 e Inception-ResNet V1
MobileNet
MobileNet foi desenvolvida para ser uma rede neural pequena, rápida e fácil de integrar em apps para celulares. Para isso ela usa um conceito novo para reduzir a sua complexidade computacional: Depthwise Separable Convolutions.
Depthwise Separable Convolution
A convolução separável profundidade-a-profundidade (Depthwise Separable Convolution) é um conceito de convoluções fatorizadas baseado em duas componentes: toda convolução padrão é fatorizada em (a) uma convolução profundidade-a-profundidade e (b) uma convolução 1×1 que os autores chamam de convolução puntual (pointwise convolution). A convolução profundidade-a-profundidade implica, na prática, na aplicação de uma convolução separada a cada canal do sinal de entrada. A convolução puntual é então usada para combinar os resultados dessas convoluções separadas. No artigo os autores demonstram que essa quebra reduz drasticamente a complexidade dos cálculos. MobileNet emprega tanto batchnorm como não-linearidades ReLU para ambas as camadas.
Links:
- Artigo: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications – Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
- Medium::Why MobileNet and Its Variants (e.g. ShuffleNet) Are Fast
- hackernoon::Creating insanely fast image classifiers with MobileNet in TensorFlow
- Usando MobileNet em conjunto com outras arquiteturas para detecção de objetos e segmentação semântica:
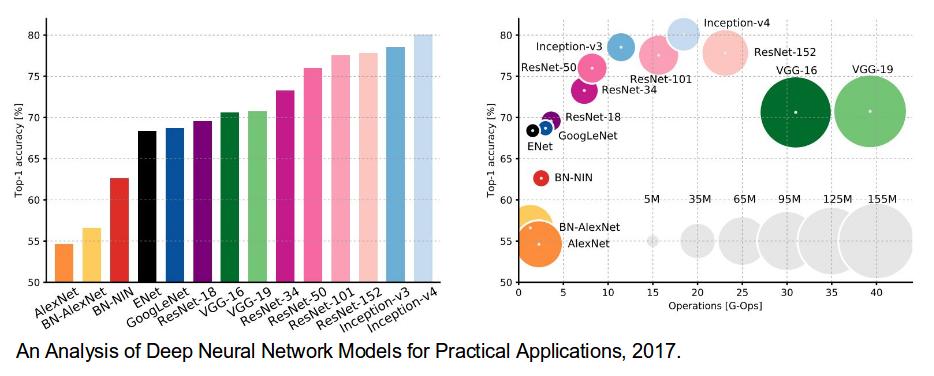
Comparação das Redes
Tutoriais
Reconhecimento de Imagens
Usando Keras e TF
- Satya Mallick: Keras Tutorial : Using pre-trained ImageNet models | Learn OpenCV
- pyimagesearch::ImageNet: VGGNet, ResNet, Inception, and Xception with Keras
- TensorFlow: Image Recognition
Usando PyTorch:
- fast.ai: Recognizing cats and dogs
- Towards Data Science: ResNet for Traffic Sign Classification With PyTorch
- Towards Data Science::Meta Tagging Shoes with Pytorch CNNs
Usando a Tensorflow Object Detection API:
Usando JavaScript
Reconhecimento de Faces, Poses & outras Coisas
Usando OpenCV DNN diretamente
- Satya Mallick: Detecção de Poses usando VGG + novas camadas. Deep Learning based Human Pose Estimation using OpenCV
- Medium::New Datasets for 3D Human Pose Estimation

Assuntos Específicos
Como avaliar e validar a qualidade do seu modelo?
- Reconhecimento de Padrões::Avaliando, Validando e Testando o seu Modelo: Metodologias de Avaliação de Performance
Detecção de Faces, etc
Estratégias de Treinamento, Geração de Dados, etc
Links & Publicações
Redes Tradicionais
- Weibo Liu, Zidong Wang, Xiaohui Liu, Nianyin Zeng, Yurong Liu, and Fuad E. Alsaadi. A survey of deep neural network architectures and their applications. Neurocomputing, 234:11 – 26, 2017. DOI: 10.1016/j.neucom.2016.12.038.
- K. Simonyan, A. Zisserman . Very Deep Convolutional Networks for Large-Scale Image Recognition, 2014. arXiv:1409.1556.
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna: “Rethinking the Inception Architecture for Computer Vision”, 2015. arXiv:1512.00567.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016. arXiv:1512.03385.
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: . CoRR, abs/1704.04861, 2017.
YOLO (veja nossa página:Deep Learning::Detecção de Objetos em Imagens)
- YOLO v3
- You Only Look Once: Unified, Real-Time Object Detection – Redmon, CVPR 2016
- YOLO 9000: Better, Faster, Stronger – Redmon, CVPR 2017
Datasets e Modelos Prontos
- PyTorch – pretrained torchvision examples
- ImageNet Tree View
- J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, ImageNet: A Large-Scale Hierarchical Image Database. IEEE Computer Vision and Pattern Recognition (CVPR), 2009.
- COCO – Common Objects in Context
- The PASCAL Visual Object Classes
- Kitti Road dataset com download daqui
- Photo Aesthetics Ranking Network with Attributes and Content Adaptation
- AVA: A Large-Scale Database for Aesthetic Visual Analysis
Copyright © 2018 Aldo von Wangenheim/INCoD/Universidade Federal de Santa Catarina